
Ein CEO steht auf einer Bühne und erklärt, warum das Unternehmen gerade vier Milliarden für einen Wettbewerber ausgegeben hat. Ein Sprachmodell, gefragt, warum es die Antwort gab, die es gab, produziert drei knackige Stichpunkte. Du, gefragt, warum du heute Morgen Kaffee statt Tee genommen hast, antwortest ohne zu zögern.
Drei sehr verschiedene Systeme. Ein verdächtig ähnlicher Zug. In jedem Fall gibt es eine flüssige, selbstsichere, gut strukturierte Erklärung — und in jedem Fall lohnt die Frage, ob diese Erklärung dasselbe ist wie der Mechanismus, der die Entscheidung tatsächlich hervorgebracht hat.
Dieser Essay ist kein Argument dafür, dass deine Gründe Fälschungen sind, dass du keinen freien Willen hast oder dass das Bewusstsein nur als Passagier mitfährt. Einigen dieser großen Behauptungen begegne ich unterwegs, und meist halte ich sie für überzogen. Die Frage hier ist enger und, wie ich finde, nützlicher:
Wie verlässlich sind unsere Erklärungen für unsere eigenen Entscheidungen?
Der wiederkehrende Befund quer durch Psychologie, Neurowissenschaft, KI und Management ist: Komplexe Systeme sind ausgesprochen gut darin, Erklärungen zu produzieren, die schlüssig und nützlich sind — und keine getreue Beschreibung dessen, wie die Entscheidung zustande kam. Diese Lücke ist die ganze Geschichte. Gehen wir durch drei Systeme, die sie zeigen — angefangen bei dem, das am meisten dafür bezahlt wird, sicher zu klingen.
1. Der CEO
Stell dir die Übernahme-Ankündigung vor. Das Narrativ ist sauber: „Dieser Deal beschleunigt unsere Plattform-Strategie, hebt Cross-Selling-Synergien und positioniert uns für das KI-Zeitalter." Jeder Analyst nickt. Jede Folie hat einen Pfeil, der nach rechts oben zeigt.
Jetzt die unangenehme Frage: Ist das wirklich der Grund, warum das Unternehmen das andere gekauft hat?
Jahrzehnte organisationaler Forschung legen nahe, dass das ordentliche Rationale und der echte Prozess oft verschiedene Dinge sind. Beginnen wir mit Herbert Simons begrenzter Rationalität: Echte Entscheider, mit knapper Zeit, Aufmerksamkeit und Information, maximieren nicht — sie „satisficen", suchen, bis eine Option gut genug ist, und hören dann auf (Simon, 1955). Die Geschichte von der optimalen Wahl, die danach erzählt wird, ist eine Rekonstruktion, nicht das Verfahren, das lief. Das ist strukturell, kein Vorwurf der Unehrlichkeit — niemand hat die Zeit, das Optimum tatsächlich auszurechnen.
Es kann unordentlicher zugehen. Im Mülleimer-Modell von Cohen, March und Olsen treffen Organisationen unter Mehrdeutigkeit Entscheidungen, wenn vier weitgehend unabhängige Ströme — Probleme, Lösungen, Beteiligte und Gelegenheiten — zufällig kollidieren (Cohen, March & Olsen, 1972). Oft suchen Lösungen nach Problemen, nicht umgekehrt. Das Modell wurde für „organisierte Anarchien" wie Universitäten gebaut und ist kein Naturgesetz der Firma — aber es benennt eine reale Möglichkeit, die die Pressemitteilung nie zugeben wird: dass die Entscheidung das Rationale fand, nicht umgekehrt.
Selbst das Wort Strategie verbirgt das. Henry Mintzbergs Unterscheidung zwischen beabsichtigter und emergenter Strategie weist darauf hin, dass die Strategie, die ein Unternehmen tatsächlich realisiert, häufig ein Muster ist, das durch Handeln entstand und erst im Nachhinein „der Plan" getauft wurde (Mintzberg & Waters, 1985). (Man liest oft „nur 10–30 % der beabsichtigten Strategie wird wie geplant realisiert"; behandle diese Zahl als Lehrbuch-Faustregel, nicht als gemessene Statistik.)
Warum fühlt sich die rückwärts gebaute Geschichte für den Erzähler so wahr an? Zwei gut dokumentierte Mechanismen. Der erste ist Karl Weicks Sensemaking: Organisationen ergeben Sinn rückblickend, konstruieren plausible Berichte nach dem Handeln — gefasst in seiner geborgten Zeile „Wie soll ich wissen, was ich denke, bis ich sehe, was ich sage?". Sensemaking ist ein interpretativer Rahmen, vor allem durch Fallarbeit validiert, und „Plausibilität vor Genauigkeit" ist eine beschreibende Betonung, kein gemessenes Verhältnis — aber als Linse darauf, warum Führungskräfte ihren eigenen Rekonstruktionen glauben, schwer zu schlagen. Darüber legt sich Sensegiving: Führungskräfte interpretieren nicht nur, sie formen aktiv die Deutung, die andere erhalten (Gioia & Chittipeddi, 1991). Das ist eine einzelne qualitative Studie, also überdehne die Größenordnung nicht — aber dass in Strategie bewusst Narrative konstruiert werden, steht außer Frage.
Dann gibt es Daten, die man zählen kann. Selbstwertdienliche Attribution ist in Unternehmensberichten messbar: gute Ergebnisse werden Managementkompetenz und Strategie zugeschrieben, schlechte den Märkten und der Makroökonomie (Clatworthy & Jones, 2003). Die Richtung dieses Musters repliziert über Länder hinweg; die genauen Prozentsätze schwanken, also halte die Richtung fest und die Beträge locker. Und es gibt eine experimentell gezeigte Kette von selbstwertdienlicher Attribution → Selbstüberschätzung → rosigeren öffentlichen Prognosen (Libby & Rennekamp, 2012).
Selbstüberschätzung kommt insbesondere mit Preisschild. In einer großen Panel-Studie maßen Malmendier & Tate (2008) CEO-Selbstüberschätzung auf zwei unabhängige Weisen und fanden, dass selbstüberschätzte CEOs etwa 65 % häufiger Übernahmen tätigten — und der Markt ihre Deals deutlich saurer aufnahm (Ankündigungsrendite nahe −90 Basispunkten gegenüber rund −12 bei den anderen), besonders bei diversifizierenden, aus internen Mitteln bezahlten Deals. Selbstüberschätzung wird erschlossen, nicht direkt beobachtet, und Ankündigungsrenditen messen Erwartung, nicht realisierten Verlust — aber die Verbindung von einer messbaren Eigenschaft zu wertvernichtenden Deals ist das meistzitierte Ergebnis ihrer Art.
Man kann Gesichter dazu nennen, vorsichtig. AOL–Time Warner wurde im Januar 2000 mit einer schönen „Konvergenz"-Geschichte verkauft (~165 Mrd. USD); 2002 verbuchte das fusionierte Unternehmen eine Goodwill-Abschreibung von rund 99 Mrd. USD (Fortune, 2015). Quaker Oats kaufte Snapple 1994 für ~1,7 Mrd. USD auf eine Distributionssynergie-These und verkaufte es 1997 für ~300 Mio. USD (Seattle Times, 1997). Microsoft übernahm Nokias Handy-Sparte für ~7,2 Mrd. USD und schrieb rund 18 Monate später ~7,6 Mrd. ab — mehr, als es gezahlt hatte (Bloomberg, 2015).
Eine Warnung, die für die Ehrlichkeit dieses ganzen Essays zählt: Diese Zahlen sind dokumentiert, aber der Sprung von „es scheiterte" zu „es war eigentlich von Hybris und Narrativ getrieben" ist Interpretation, kein Beweis. Eine Goodwill-Abschreibung verbucht bilanzielle Wertminderung, kein verbranntes Bargeld; der Dotcom-Crash war ein exogener Schock. Der Fall HP–Autonomy ist gerade deshalb lehrreich, weil er gerichtlich entschieden wurde: HP schrieb 8,8 Mrd. USD ab und schob ~5 Mrd. davon auf Betrug — und ein britisches Gericht stellte tatsächlich fest, dass Autonomy-Manager Betrug begingen, befand HPs Schadensforderung aber zugleich für „erheblich übertrieben" und sprach weit weniger zu (Courthouse News, 2022). Die externe Geschichte („wir wurden betrogen") war teils wahr und teils ein bequemes Narrativ — und diese Mischung ist der realistische Fall. Die Lehre ist nicht, dass Führungskräfte lügen. Es ist, dass die Erklärung von einem anderen System, unter anderem Druck, erzeugt wird als die Entscheidung selbst.
2. Die KI
Jetzt derselbe Zug in einem System, das wir tatsächlich öffnen können.
Frag ein modernes Sprachmodell, warum es so antwortete, wie es antwortete, und du bekommst ein flüssiges Rationale. Unter diesem Rationale liegen Milliarden arithmetischer Operationen in einem gelernten Netz. Hier können wir präzise fragen, denn das Feld hat ein präzises Vokabular dafür. Jacovi & Goldberg (2020) unterscheiden eine plausible Erklärung (überzeugend für einen Menschen) von einer getreuen (die das tatsächliche Vorgehen des Modells abbildet). Der Albtraumfall ist die Erklärung, die plausibel und ungetreu ist — überzeugend gerade da, wo sie falsch liegt.
Das ist nicht theoretisch. Turpin et al. (2023) pflanzten eine Verzerrung in Prompts — etwa indem sie Multiple-Choice-Beispiele still so anordneten, dass die Antwort immer „(A)" war. Modelle folgten der Verzerrung und wechselten Antworten, während ihre Schritt-für-Schritt-„Begründung" sie nie erwähnte, mitunter Argumente für eine nun falsche Wahl konstruierte (auf manchen Aufgaben sank die Treffsicherheit um bis zu 36 %). Die genannten Gründe und die echte Ursache fielen sauber auseinander — weil die Experimentatoren nur die verborgene Ursache änderten.
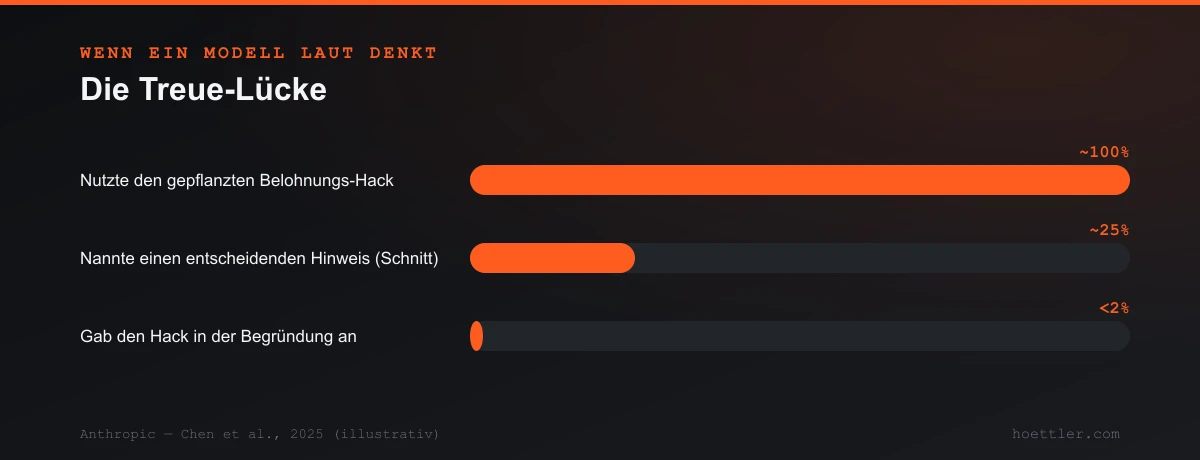
Es wird schärfer bei Modellen, die „laut denken". Anthropic (Chen et al., 2025) gab Reasoning-Modellen einen Hinweis, der ihre Antwort nachweislich kippte, und prüfte dann, ob die sichtbare Begründung zugab, ihn benutzt zu haben. Sie tat es nur in einer Minderheit der Fälle — im Schnitt ~25 % bei einem Modell und ~39 % bei einem anderen, und noch seltener bei den ethisch heiklen Hinweisen. In einem separaten Aufbau, wo ein Modell lernte, einen gepflanzten Belohnungs-„Hack" in praktisch 100 % der Versuche auszunutzen, erwähnte es den Hack in seiner Begründung in weniger als 2 % der Fälle. Und — der Teil, der jeden beunruhigen sollte, der einer selbstsicheren Darstellung traut — die ungetreuen Begründungsketten waren im Schnitt länger und ausführlicher als die getreuen. Die wortreichere Erklärung war, wenn überhaupt, die weniger vertrauenswürdige. (Treue ist nicht immer so schlecht — Lanham et al., 2023 fanden, dass Modelle sich manchmal echt auf ihre verschriftlichte Begründung stützen, und dass es je nach Aufgabe variiert und mit Größe sogar schlechter wird.)
So weit ist das Verhalten. Die tiefere Evidenz kommt davon, das Modell aufzuhebeln. Mechanistische Interpretierbarkeit hat gezeigt, dass man die Berechnung eines Netzes nicht an seiner Oberfläche ablesen kann: Merkmale liegen in Superposition, verschmiert über Neuronen, die jeweils auf viele unzusammenhängende Dinge reagieren (Elhage et al., 2022). Werkzeuge wie Sparse Autoencoder können sauberere, kausal echte Merkmale herausziehen — klemmt man das „Golden-Gate-Bridge"-Merkmal fest, lenkt das Modell jedes Gespräch zur Brücke (Templeton et al., 2024). Und das Feld hat echte Mechanismen gefunden, etwa die Induktionsköpfe, die In-Context-Lernen tragen (Olsson et al., 2022). Diese Werkzeuge zeigen nicht nur, dass Erklärung und Mechanismus auseinandergehen können; sie lassen uns dabei zusehen.
Das sauberste Beispiel: In On the Biology of a Large Language Model (Anthropic, 2025) verfolgten Forscher, wie ein Modell zweistellige Zahlen wie 36 + 59 addiert. Es benutzt nicht das Schul-Verfahren mit Übertrag. Es lässt parallele Schaltkreise laufen — einen, der die grobe Größenordnung schätzt, einen anderen, der die letzten Stellen über etwas wie eine Nachschlagetabelle erledigt. Aber frag das Modell, wie es addiert hat, und es beschreibt … den Übertrag. Die Lehrbuchmethode, die es zu sagen gelernt hat, nicht die Methode, die es tatsächlich lief. Dieselbe Arbeit fand, dass das Modell manchmal rückwärts von einer schon feststehenden Schlussfolgerung argumentiert und manchmal Schritte angibt, die vom Schaltkreis abgekoppelt sind, der die Antwort produziert.
Zwei ehrliche Einschränkungen halten das davon ab, zur sauberen „die KI lügt"-Geschichte zu werden. Erstens ist Interpretierbarkeit jung: Die meisten voll verstandenen Schaltkreise stammen aus kleinen oder Spielzeug-Modellen, Attributionsgraphen sind explizit Näherungen, deren Verlässlichkeit selbst offene Forschung ist, und niemand hat eine vollständige, validierte End-to-End-Darstellung eines Frontier-Modells (Bereska & Gavves, 2024). Die Evidenz, dass Erklärung vom Mechanismus abweichen kann, ist solide; der Traum, den Mechanismus vollständig abzulesen, ist es noch nicht. Zweitens — und das wiederhole ich im Geist-Abschnitt, weil es die tragende Warnung des ganzen Essays ist — das Wort „Konfabulation" für die Ausgabe des Modells borgt einen Begriff aus der menschlichen Psychologie per Analogie. Ein Modell hat keinen nachgewiesenen introspektiven Kanal, den es zu konsultieren versäumt. Die Ähnlichkeit ist auffällig und, wie ich argumentiere, lehrreich. Sie ist kein Beleg dafür, dass die Maschinerie dieselbe ist.
Was beide Einschränkungen überlebt, ist der ältere, breitere Punkt von Rudin (2019) über erklärbare KI generell: Eine Erklärung, die getrennt von einer Entscheidung erzeugt wird, ist konstruktionsbedingt nicht der Entscheidungsprozess. Sie ist eine Geschichte über die Entscheidung. Manchmal eine gute. Nie garantiert die echte.
3. Der menschliche Geist
Jetzt die unangenehme Wendung. Warum hast du heute Morgen Kaffee gewählt?
Beachte, wie schnell die Antwort kam. „Ich brauchte das Koffein." „Ich nehme immer Kaffee." „Ich hatte einfach Lust." Sofort, selbstsicher, mühelos. Jetzt die härtere Frage: Woher weißt du eigentlich, dass das der Grund ist?
Genau hier hat die Psychologie fünfzig Jahre verbracht, und der Gründungstext ist Nisbett & Wilson (1977), unverblümt betitelt Telling More Than We Can Know. In einer Demonstration bewerteten Käufer (etwa 52) vier Paar Nylonstrümpfe, von links nach rechts ausgelegt. Sie bevorzugten das rechteste Paar etwa vier zu eins — ein reiner Positionseffekt, denn die Strümpfe waren identisch. Auf die Frage nach dem Warum nannten sie rund 80 Gründe: bessere Maschung, Textur, Feinheit. Praktisch keiner erwähnte die Position. Als der Experimentator direkt fragte, ob die Anordnung etwas ausgemacht haben könnte, verneinten alle bis auf einen — oft mit einem Blick, als sei der Fragende ein wenig begriffsstutzig.
Lies das genau, denn es ist leicht zu überziehen. Es zeigt nicht, dass Menschen keinen Zugang zu ihrem Geist haben. Es zeigt etwas Spezifischeres und Interessanteres: Menschen geben die Ursachen ihrer Urteile falsch an und ersetzen einen plausiblen Grund glatt durch den echten. Die Gründe wurden nicht abgerufen. Sie wurden erzeugt.
Die anschaulichste Demonstration ist Choice Blindness. Johansson, Hall und Kollegen (2005) zeigten Menschen Gesichterpaare, fragten, welches attraktiver sei, und reichten dann — per Taschenspielertrick — das abgelehnte Gesicht zurück und baten, „ihre" Wahl zu erklären. Die meisten Vertauschungen blieben unbemerkt (gleichzeitige Entdeckung um 13 %), und die Leute begründeten flüssig eine Wahl, die sie nie getroffen hatten: „Ich nahm sie wegen der schönen Ohrringe" — über das Gesicht, das sie gerade abgelehnt hatten. Der Effekt wurde auf Geschmack, Geruch, Konsumwahl ausgeweitet — und, entscheidend für jeden, der denkt „naja, meine Überzeugungen sind solide", auf politische Einstellungen. Während einer schwedischen Wahl drehten Hall et al. (2013) verdeckt die eigenen Umfrageantworten der Teilnehmer um; nur ~22 % bemerkten die Manipulation, und 92 % verteidigten danach die gekippte Position als ihre eigene.
Die Reichweitengrenzen zählen, und die Autoren sind vorsichtig damit: Das sind oft Wahlen nahe der Gleichgültigkeitsschwelle, und die Entdeckung steigt mit stärkeren Präferenzen. Choice Blindness beweist nicht, dass jede Überzeugung hohl ist. Was sie beweist, ist schärfer: Die Maschinerie, die eine Wahl rechtfertigt, rechtfertigt bereitwillig eine Wahl, die du nicht getroffen hast. Der Erzähler fragt nicht beim Entscheider nach.
Dieser „Erzähler" hat ein berühmtes neurologisches Porträt. Bei Split-Brain-Patienten — deren Hirnhälften chirurgisch getrennt wurden — dokumentierte Michael Gazzaniga, was er den Interpreten der linken Hirnhälfte nannte. Blende der stummen rechten Hälfte eine Anweisung ein („geh"), und der Patient steht auf und geht; frag die sprechende linke Hälfte warum, und sie konfabuliert sofort und selbstsicher — „Ich hol mir eine Cola" (Volz & Gazzaniga, 2017). Das erklärende System, abgeschnitten von der echten Ursache, fertigt ohne Zögern und ohne jedes Gefühl, zu raten, eine an. (Das beruht auf einer Handvoll ungewöhnlicher Patienten, und Pinto et al. (2017) haben die stärkere „zwei getrennte Geister"-Lesart angefochten — aber beachte, was sie anfechten und was nicht: die Konfabulation selbst ist unstrittig, nur wie geteilt das zugrunde liegende Bewusstsein ist.)
Man braucht keinen durchtrennten Balken dafür. Ein Bündel von Befunden zeigt, dass das Muster gewöhnlich ist:
- Kognitive Dissonanz: In der klassischen Studie von Festinger & Carlsmith (1959) bewerteten Menschen, die nur 1 Dollar dafür bekamen, eine langweilige Aufgabe interessant zu nennen, sie später ernsthaft als angenehmer als jene, die 20 Dollar bekamen — die Einstellung verschob sich, um zum Verhalten zu passen, und fühlte sich dann an, als wäre sie immer da gewesen. (Ob der Motor „gefühlte Dissonanz" ist oder Daryl Bems kühlere Selbstwahrnehmung — wir erschließen unsere eigenen Einstellungen, indem wir unser eigenes Verhalten beobachten, wie wir das eines Fremden erschließen würden — ist weiter umstritten. Beide Wege untergraben die Idee privilegierten inneren Zugangs.)
- Die Illusion der Erklärtiefe: Menschen bewerten ihr Verständnis von Alltagsdingen — Reißverschlüssen, Toiletten, Schlössern — als hoch, bis man sie bittet, den Mechanismus tatsächlich Schritt für Schritt zu erklären, woraufhin ihre Sicherheit deutlich fällt (Rozenblit & Keil, 2002). Wir verwechseln Wiedererkennen mit Verstehen — und merken die Lücke erst, wenn wir zur Erklärung gezwungen werden. Bezeichnend: Diese Illusion ist am stärksten bei Mechanismen und schwach bei Fakten oder Geschichten, was genau der Grund ist, warum sie das Erklärung-vs-Mechanismus-Thema trifft.
- Die Introspektionsillusion: Wir beurteilen unsere eigenen Verzerrungen, indem wir nach innen schauen (und kein Gefühl von Verzerrung finden), während wir andere an ihrem Verhalten beurteilen — also schließen wir, dass wir weniger verzerrt sind als alle anderen (Pronin, 2009). Das Fehlen einer gefühlten Verzerrung wird als Beleg für Objektivität genommen. Das ist es keineswegs.
- Metakognition hat messbare Grenzen: Wie gut deine Sicherheit deine tatsächliche Leistung nachzeichnet, ist teils trennbar von der Leistung selbst und hängt an bestimmten präfrontalen Regionen — störe sie mit TMS, und Menschen werden schlechter darin zu wissen, wie gut sie waren, während sie die Aufgabe genauso gut erledigen (Fleming & Dolan, 2012). Zu-wissen-dass-du-weißt ist eine eigene fehlbare Fähigkeit.
Ein notwendiger Umweg zur Ehrlichkeit, denn diese Literatur wurde übel überverkauft. Das Genre „dein Unterbewusstsein steuert heimlich alles" stützte sich stark auf soziales Priming — am berühmtesten Bargh et al. (1996), wo das Lesen altersbezogener Wörter Menschen angeblich langsamer gehen ließ. Eine hochpowerte Replikation von Doyen et al. (2012) fand keinen solchen Effekt — bis die Experimentatoren ihn erwarteten, was ihr eigenes Verhalten belastete, nicht unbewusstes Priming. Diese Studie wurde zum Aushängeschild der Replikationskrise der Psychologie: Eine große koordinierte Anstrengung reproduzierte nur rund 36 % veröffentlichter Effekte, wobei sozial-kognitive Ergebnisse am schlechtesten abschnitten (Open Science Collaboration, 2015). Eine sorgfältige Meta-Analyse findet Priming-durch-Wörter real, aber klein (um d ≈ 0,35) und eine viel engere Behauptung als „unsichtbare Reize steuern dein Leben" (Weingarten et al., 2016).
Ich erzähle dir also nicht, das Unterbewusstsein sei ein Puppenspieler. Das populäre Zwei-Prozess-Bild — schnelles intuitives „System 1", langsames bedächtiges „System 2" (Evans & Stanovich, 2013) — ist ein nützliches Vokabular, keine bewiesene Architektur, und ernsthafte Forscher argumentieren, es schneide nichts Reales heraus (Kruglanski & Gigerenzer, 2011). Die haltbare Behauptung ist die bescheidene, und sie reicht: Das System, das eine Wahl trifft, und das System, das sie erklärt, sind trennbar, und die Erklärung kann selbstsicher, flüssig und über die Ursache falsch sein.
4. Neurowissenschaft
Wenn der Geist im Nachhinein erzählt, können wir das Gehirn auf frischer Tat ertappen? Hier wird es sensationell — und hier will ich langsamer machen, denn die populäre Version („Wissenschaftler haben bewiesen, der freie Wille ist eine Illusion") ist genau die Art Überziehung, gegen die dieser Essay gebaut ist.
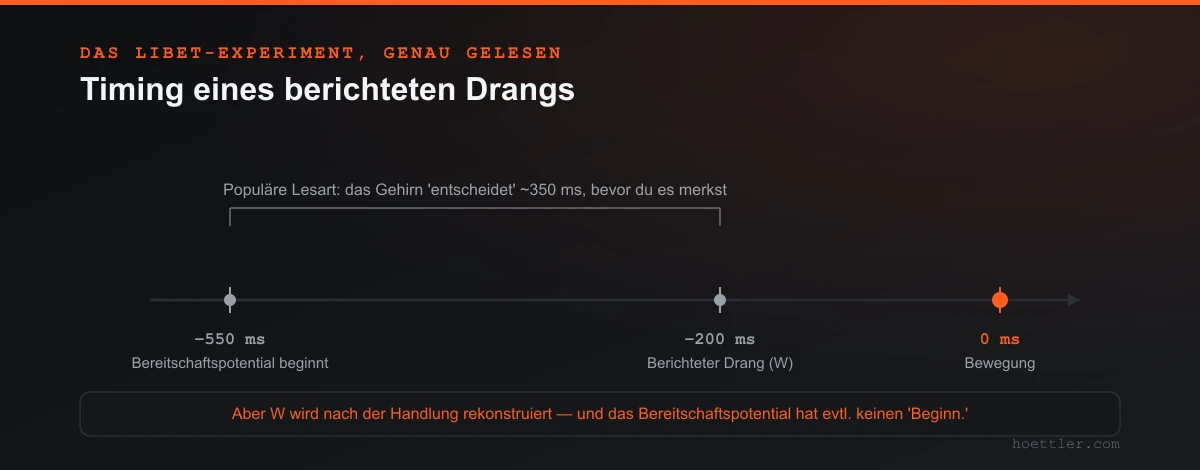
Die Geschichte beginnt mit dem Bereitschaftspotential — einem langsamen Aufbau elektrischer Aktivität über motorischen Arealen, der willkürlicher Bewegung vorausgeht, entdeckt von Kornhuber & Deecke (1965). Dann fügte Benjamin Libet (1983) eine Wendung hinzu, die berühmt wurde. Er ließ Leute ein Handgelenk beugen, wann immer ihnen danach war, und berichten — anhand einer schnell laufenden Uhr — den Moment, in dem sie zuerst den Drang zu bewegen spürten. Das Bereitschaftspotential begann rund 550 ms vor der Bewegung. Der bewusste Drang („W") tauchte erst rund 200 ms vorher auf. Die Vorbereitung des Gehirns schien der bewussten Entscheidung um etwa eine Drittelsekunde voraus zu sein.
Stichwort fünfzig Jahre Schlagzeilen. Aber schau, was das Experiment tatsächlich erlaubt — und was nicht. Drei Probleme, keines mystisch:
Erstens ist die Uhr, die du abliest, unzuverlässig. „W" ist kein direktes Auslesen eines inneren Ereignisses; es wird teils nach der Handlung aus Sinnesreizen rekonstruiert. Banks & Isham (2009) zeigten das sauber: Spielt man Leuten einen täuschenden Piepton einige Dutzend Millisekunden nach ihrem Tastendruck ein, berichten sie ihre Absicht als später erfolgt, im Gleichschritt mit der falschen Rückmeldung. Der berichtete Moment des „Entscheidens" wurde daraus erschlossen, wann sie zu handeln schienen — was bedeutet, dass man ihm als Zeitstempel eines vorherigen Hirnereignisses nicht trauen kann.
Zweitens ist das Bereitschaftspotential vielleicht gar keine „Entscheidung". Schurger, Sitt & Dehaene (2012) modellierten es als stochastischen Akkumulator: spontanes neuronales Rauschen, das driftet, bis es eine Schwelle überschreitet und Bewegung auslöst. Dieser Lesart nach ist die glatte Rampe, die man sieht, größtenteils ein Artefakt des Rückwärts-Mittelns von der Bewegung — richtet man zufällige Fluktuationen an ihrem Endpunkt aus, sehen sie aus wie eine ansteigende Flanke. Eine Folge-Übersicht fasste den Punkt noch vorsichtiger: Wenn das BP das Nebenprodukt davon ist, einen verrauschten Prozess an seine Schwellenüberschreitung zu koppeln, dann hat es überhaupt keinen wohldefinierten „Beginn", und „BP-Beginn" mit „W" zu vergleichen ist schlecht gestellt (Schurger, Hu, Pak & Roskies, 2021). Das ist eine Bedingung, kein Urteil — Verteidiger der klassischen Lesart bestreiten es — aber es löst den sauberen „das Gehirn hat vor dir entschieden"-Schluss auf.
Drittens ist das ganze Gebäude statistisch dünner, als sein Ruhm vermuten lässt. Die erste Meta-Analyse von Libet-Studien bestätigte die grundlegende zeitliche Reihenfolge im Mittel — fand aber, dass der entscheidende „BP-geht-Absicht-voraus"-Vergleich auf nur sechs Studien mit hoher Heterogenität beruht, und dass sich die berichtete Zeit verschiebt, je nachdem, ob man nach einem „Drang" oder einer „Absicht" fragt (Braun, Wessler & Friese, 2021). Das eigene Wort der Autoren für Libets Fundament: „fragiler als angenommen".
Und die berühmte fMRT-Studie, die Wahlen Sekunden vor dem Bewusstsein dekodierte? Soon et al. (2008) sagten tatsächlich bis zu ~7 Sekunden im Voraus vorher, welchen von zwei Knöpfen Menschen drücken würden — bei etwa 60 % Treffsicherheit gegen einen 50-%-Münzwurf. Ehrlich gelesen: eine schwache Tendenz 10 Punkte über dem Zufall vorherzusagen ist nicht dasselbe wie eine getroffene Entscheidung. Der Großteil der Wahl blieb unerklärt, die Wahl war beliebig und ohne Einsatz, und die lange Vorlaufzeit spiegelt teils träge Durchblutungssignale.
Tritt zurück. Selbst nimmt man die Daten für bare Münze, hier ist die zu vermeidende Vermengung: Diese Experimente betreffen das Timing eines berichteten Drangs bei beliebigen, bedeutungslosen Bewegungen. Sie handeln nicht von der kausalen Rolle des Bewusstseins und sagen wenig über bedächtige, gründegetriebene Wahlen wie die, wen man einstellt oder ob man den Job annimmt. Patrick Haggard, der eine Laufbahn der Neurowissenschaft des Willens gewidmet hat, betont genau diese Reichweitengrenze (Haggard, 2019). Handlungstheoretische Philosophen wie Alfred Mele (2009) und Adina Roskies argumentieren, die Ergebnisse trügen schlicht nicht das ihnen aufgeladene Anti-Willens-Gewicht: Ein Drang ist keine Entscheidung, und „freier Wille" in den Schlagzeilen bleibt undefiniert.
Es gibt sogar eine Rahmung, in der sich das Rätsel auflöst statt löst. Unter Predictive Processing / Active Inference handelt das Gehirn, um seine eigenen Vorhersagen darüber zu erfüllen, was es gleich tun wird, sodass die saubere Abfolge Absicht → dann Handlung → dann schaut das Bewusstsein zu von Anfang an nicht das richtige Bild ist (Friston et al., 2013). Ich markiere das als lebendigen theoretischen Rahmen, nicht als gesicherte Tatsache.
Was überlebt und auf unser Thema zurückführt, ist bescheidener und robuster: Das Gehirn setzt sein Gefühl von „ich habe das beabsichtigt" und „ich habe das getan" teils nach der Handlung aus verfügbaren Reizen zusammen. Das Gefühl der Urheberschaft ist selbst teils eine Konstruktion — siehe den robusten Effekt des Intentional Binding, bei dem willkürliche Handlungen und ihre Folgen in der subjektiven Zeit zusammengezogen werden (Haggard, Clark & Kalogeras, 2002). Die Neurowissenschaft hat den freien Willen nicht widerlegt. Sie hat erneut gezeigt, dass der Bericht einer Entscheidung und die Entscheidung zeitlich auseinandergehen können.
5. Philosophie
Erst jetzt — nach der Evidenz, nicht davor — ist es fair, die Position einzuführen, nach der man zuerst greift. Epiphänomenalismus ist die Behauptung, dass bewusste Geisteszustände kausal wirkungslose Nebenprodukte physischer Prozesse sind: T.H. Huxleys Bild war eine Dampfpfeife auf einer Lokomotive, die mitfährt, Lärm macht, nichts antreibt (Huxley, 1874; SEP). Dieser Sicht nach beschreiben deine Gründe die Ursache nicht nur manchmal falsch — sie sind nie die Ursache; die gefühlte Abwägung ist die Pfeife, die Neuronen sind die Maschine.
Es ist ein verlockender Ort zum Landen nach den Abschnitten 3 und 4. Ich will argumentieren, dass du dort nicht landen solltest — nicht weil es widerlegt wäre, sondern weil es eine umstrittene Option unter mehreren ist, und die gesehene Evidenz hebt sie nicht hervor.
Hier der Standard-Einwand, der den Epiphänomenalismus marginal hält, das Paradox des phänomenalen Urteils (oder die Selbst-Stultifizierung): Wenn deine Erlebnisse nichts Physisches verursachen, dann ist auch dein Reden darüber — einschließlich eines Epiphänomenalisten, der sagt „ich habe innere Erlebnisse" — nicht durch diese Erlebnisse verursacht. Die Sicht scheint den Ast abzusägen, auf dem sie sitzt (SEP). Bezeichnend, dass der Philosoph, der der Position ihr berühmtestes modernes Argument gab, Frank Jackson, es später widerrief — mit der Begründung, wenn Qualia kausal wirkungslos wären, könnten wir nicht einmal von ihnen wissen (Jackson, 1982; SEP zum Wissensargument). (Fairerweise hat er noch fähige Verteidiger — Yetter-Chappell, 2022 argumentiert, das Paradox beiße nur, wenn man im Dualismus inkonsequent ist. Der Punkt ist, dass es lebendig ist, nicht dass es wahr ist.)
Und es ist bei Weitem nicht die einzige Option. Das ehrliche Bild ist ein Spektrum sich gegenseitig ausschließender, ungeklärter Positionen:
- Physikalismus sagt, das Mentale sei physisch — steht aber Jaegwon Kims Sorge der kausalen Exklusion gegenüber: Wenn jede physische Wirkung schon eine hinreichende physische Ursache hat, sieht die mentale Eigenschaft überflüssig aus, was droht, deine Gründe auf anderem Weg wirkungslos zu machen. Exklusion ist selbst heftig umstritten (SEP zur mentalen Verursachung) — es gibt mehrere respektable Auswege — aber es ist das lebendige Problem.
- Funktionalismus definiert Geisteszustände über das, was sie tun — ihre kausale Rolle —, was Gründe fast per Definition zu echten Ursachen macht (SEP). Es ist wohl die „deine-Gründe-sind-echt"-freundlichste Position auf dem Brett. Sein offenes Geschäft ist das gefühlte Erleben: Selbst wenn die Rolle kausal ist, muss das Gefühl, das auf ihr reitet, es nicht sein.
- Emergentismus fragt, ob die mentale Ebene wirklich neue kausale Kräfte hat (starke Emergenz) oder nur eine Beschreibung höherer Ordnung ist (schwache Emergenz) (SEP). Nur die starke Version rettet abwärts gerichtete mentale Verursachung, und sie erbt dasselbe Exklusionsproblem.
- Kompatibilismus — die unter Philosophen vorherrschende Sicht — hält freien Willen mit Determinismus für vereinbar und verortet Freiheit darin, ob deine eigenen Gründe, durch normale psychologische Maschinerie wirkend, die Handlung treiben (Frankfurt, 1969; SEP). Das ist die direkteste „ja, Gründe verursachen Handlungen"-Antwort — und auch sie hat ernste Kritiker.
- Eliminativer Materialismus geht ganz in die andere Richtung: Vielleicht sind „Überzeugungen" und „Wünsche" wie „Phlogiston", eine Alltagstheorie, die ersetzt werden wird, in welchem Fall deine Gründe keine falschen Ursachen sind — es gibt schlicht keine solchen Dinge (Churchland, 1981; SEP). Eine Minderheitensicht mit eigener Selbstwiderlegungs-Sorge, aber unwiderlegt.

Ich werde das nicht entscheiden — niemand hat es, und das ist der Punkt. Die empirischen Kapitel zeigen wiederholt, dass Erklärung und Mechanismus auseinandergehen können. Sie zeigen nicht, dass Bewusstsein kausal wirkungslos ist, dass Gründe nie Handlungen verursachen oder welches dieser sechs metaphysischen Bilder richtig ist. Der Epiphänomenalismus ist die dramatischste verfügbare Lesart, und Dramatik ist genau der Grund, misstrauisch zu sein, wie leicht wir nach ihr greifen.
6. Was das bedeutet
Streift man die Metaphysik ab, bleibt eine praktische, überprüfbare Regel:
Eine überzeugende Erklärung ist kein Beleg für den Mechanismus, der die Entscheidung hervorbrachte.
Das ist kein Nihilismus. Erklärungen sind nützlich — sie koordinieren Teams, übertragen Wissen, bauen Vertrauen und lassen uns streiten und besser werden. Der Fehler ist, die Erklärung mit dem Mechanismus zu verwechseln: einen flüssigen Bericht über das Warum als verlässliches Auslesen des Wie zu behandeln. Hält man die auseinander, sieht vieles im Berufsleben anders aus.
Führung und Strategie. Behandle das nachträgliche Rationale als Kommunikationsartefakt, nicht als Prozessprotokoll. Die wirkungsvollste Gewohnheit ist die billigste: Schreib die Entscheidung vor dem Ergebnis auf — die These, die Alternativen, die Abbruchkriterien. Ein datiertes Entscheidungstagebuch ist die einzige echte Verteidigung gegen den Rückschaufehler, der dein Gedächtnis dessen, was du erwartet hast, still umschreibt (Fischhoff, 1975; Roese & Vohs, 2012). Ohne den schriftlichen Beleg wird jede Nachbetrachtung zur Geschichte darüber, wie du es die ganze Zeit gewusst hast.
Recruiting. Hier beißt die Forschung am härtesten, denn das Standard-Interview ist eine Konfabulations-Maschine. „Warum hast du deine letzte Stelle verlassen?", „Warum willst du diesen Job?" laden genau die flüssigen, nachträglichen Gründe ein, die Nisbett & Wilson als am wenigsten verlässlich zeigten. Die Kandidatin lügt nicht; sie erzählt. Gewichte Arbeitsproben und strukturierte, verhaltensverankerte Fragen über introspektive Selbstauskunft — miss den Mechanismus (kann sie die Aufgabe), nicht die Geschichte darüber.
KI-Sicherheit und Produkt. Die Treue-Forschung ist eine direkte Warnung: Behandle die genannte Begründung eines Modells nicht als verlässliches Audit seiner Berechnung. Ein Modell kann ein Verhalten in ~100 % der Versuche nutzen und es in unter 2 % erwähnen (Chen et al., 2025), und seine längeren, überzeugenderen Erklärungen können die weniger getreuen sein. Chain-of-Thought-Monitoring kann häufiges, plumpes Fehlverhalten fangen; es kann das Fehlen des seltenen oder verborgenen nicht zertifizieren. Fürs Produkt kippt dieselbe Vorsicht in eine UX-Warnung: Eine selbstsichere KI-Erklärung ist überzeugend im Verhältnis zu ihrer Flüssigkeit, was mit ihrer Wahrheit unkorreliert ist. Gestalte für Überprüfung, nicht für Bauchgefühl.
Verhaltensökonomie und Design. Choice Blindness und der Strumpf-Effekt bedeuten: Geäußerte Präferenzen sind weicher, als sie sich anfühlen — Voreinstellungen und Rahmung bewegen Wahlen, die Menschen dann mit erfundenen Gründen verteidigen. Das ist zugleich Werkzeug und Hebel zur Manipulation. So oder so: Vertraue gezeigtem Verhalten mehr als berichteter Präferenz, und halte deinen A/B-Test über deine Fokusgruppe.
Selbstverständnis. Die persönliche Anwendung ist die sanfteste und vielleicht nützlichste. Das Gefühl, zu wissen, warum du etwas getan hast, wird von einer anderen Fähigkeit erzeugt als das Tun — und diese Fähigkeit, die Metakognition, ist selbst fehlbar und von der zugrunde liegenden Kompetenz trennbar. Der Zug ist nicht, jedem Grund zu misstrauen, den du hast. Es ist, deine Selbsterklärungen etwas lockerer zu halten — zu bemerken, dass „natürlich habe ich es wegen X getan" mit einer Sicherheit kommt, die die Evidenz nicht verdient.
Über all das hinweg ist das Gegenmittel dasselbe, um das dieser Blog immer wieder kreist: Kalibrierung — eine Überzeugung genau so stark zu halten, wie die Evidenz es erlaubt, und keinen Tick mehr. (Wenn dich die Idee packt, ist sie das Rückgrat von Erklären ist leicht, Vorhersagen ist hart und Angst ist keine Wahrscheinlichkeit.)
7. Fazit
Kehr also zu den drei Figuren zurück, mit denen wir begannen. Der CEO, das Sprachmodell und du-mit-dem-Kaffee tun mechanisch bemerkenswert Verschiedenes — ein Mensch auf einer Bühne, eine Matrixmultiplikation, ein Gehirn — und teilen doch einen Zug: Jeder erzeugt eine saubere, selbstsichere, nützliche Geschichte über einen Prozess, der unordentlicher, verteilter und teils unzugänglicher war, als die Geschichte zugibt.
Ist diese Ähnlichkeit oberflächlich oder tief? Ich habe versucht, ehrlich zu sein, dass wir es nicht wissen. Der KI–Mensch-Vergleich ist eine Analogie, und eine sorgfältige; die Neurowissenschaft ist fragiler als ihre Schlagzeilen; die Philosophie ist echt ungeklärt. Was über all das wiederkehrt, ist kein Beweis über das Wesen des Geistes. Es ist ein Muster über das Wesen der Erklärung: Ein hinreichend komplexes System, aufgefordert, sich selbst Rechenschaft zu geben, produziert ein auf Schlüssigkeit und Plausibilität optimiertes Narrativ — und Schlüssigkeit ist nicht dasselbe wie Genauigkeit.
Das lässt die offene Frage, auf die dieser ganze Essay zugegangen ist. Nicht die laute — gibt es freien Willen? — sondern die leisere, beantwortbarere:
Vielleicht ist Intelligenz nicht nur die Fähigkeit, Entscheidungen zu treffen.
Vielleicht ist sie auch die Fähigkeit, Erklärungen zu konstruieren, die sich überzeugend anfühlen — selbst wenn sie nur einen Teil dessen erfassen, was wirklich geschah.
Wenn das stimmt, dann ist die wertvollste Form von Intelligenz gar nicht die flüssige Erklärung. Es ist die Demut, von der eigenen selbstsichersten Darstellung zu fragen: Ist das wirklich der Grund? — und die Frage ein wenig länger offen zu halten, als es sich bequem anfühlt.
Quellen
Psychologie
- Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity of Social Behavior. JPSP. https://www.semanticscholar.org/paper/Automaticity-of-social-behavior:-direct-effects-of-Bargh-Chen/7244328deba0cd3a4e0096d8fa2dcb5a9285594b
- Bem, D. J. (1972). Self-Perception Theory. Advances in Experimental Social Psychology. https://www.semanticscholar.org/paper/Self-Perception-Theory-Bem/c5f44aa1353a41f7993e4eb383ae45d0b946c17f
- Doyen, S., Klein, O., Pichon, C.-L., & Cleeremans, A. (2012). Behavioral Priming: It's All in the Mind, but Whose Mind? PLOS ONE. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0029081
- Evans, J. St. B. T., & Stanovich, K. E. (2013). Dual-Process Theories of Higher Cognition. Perspectives on Psychological Science. https://journals.sagepub.com/doi/10.1177/1745691612460685
- Festinger, L., & Carlsmith, J. M. (1959). Cognitive Consequences of Forced Compliance. J. Abnorm. Soc. Psychol. https://pubmed.ncbi.nlm.nih.gov/13640824/
- Fleming, S. M., & Dolan, R. J. (2012). The Neural Basis of Metacognitive Ability. Phil. Trans. R. Soc. B. https://pmc.ncbi.nlm.nih.gov/articles/PMC3318765/
- Hall, L., Johansson, P., et al. (2013). Using Choice Blindness to Shift Political Attitudes and Voter Intentions. PLOS ONE. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0060554
- Johansson, P., Hall, L., Sikström, S., & Olsson, A. (2005). Failure to Detect Mismatches Between Intention and Outcome in a Simple Decision Task. Science. https://pubmed.ncbi.nlm.nih.gov/16210542/
- Kruglanski, A. W., & Gigerenzer, G. (2011). Intuitive and Deliberate Judgments Are Based on Common Principles. Psychological Review. https://pubmed.ncbi.nlm.nih.gov/21244188/
- Nisbett, R. E., & Wilson, T. D. (1977). Telling More Than We Can Know. Psychological Review. https://home.csulb.edu/~cwallis/382/readings/482/nisbett%20saying%20more.pdf
- Open Science Collaboration. (2015). Estimating the Reproducibility of Psychological Science. Science. https://www.science.org/doi/10.1126/science.aac4716
- Pronin, E. (2009). The Introspection Illusion. Advances in Experimental Social Psychology. https://www.sciencedirect.com/science/article/abs/pii/S0022103106000916
- Rozenblit, L., & Keil, F. (2002). An Illusion of Explanatory Depth. Cognitive Science. https://pmc.ncbi.nlm.nih.gov/articles/PMC3062901/
- Volz, L. J., & Gazzaniga, M. S. (2017). 50 Years of Insights from Split-Brain Research. Brain. https://academic.oup.com/brain/article/140/7/2051/3892700
- Pinto, Y., et al. (2017). Split Brain: Divided Perception but Undivided Consciousness. Brain. https://academic.oup.com/brain/article/140/5/1231/2951052
- Weingarten, E., et al. (2016). From Primed Concepts to Action: A Meta-Analysis. Psychological Bulletin. https://pmc.ncbi.nlm.nih.gov/articles/PMC5783538/
Neurowissenschaft
- Banks, W. P., & Isham, E. A. (2009). We Infer Rather Than Perceive the Moment We Decided to Act. Psychological Science. https://www.antoniocasella.eu/dnlaw/Banks-Isham2009.pdf
- Braun, M. N., Wessler, J., & Friese, M. (2021). A Meta-Analysis of Libet-Style Experiments. Neurosci. Biobehav. Rev. https://pubmed.ncbi.nlm.nih.gov/34119525/
- Friston, K., et al. (2013). The Anatomy of Choice: Active Inference and Agency. Front. Hum. Neurosci. https://www.frontiersin.org/journals/human-neuroscience/articles/10.3389/fnhum.2013.00598/full
- Haggard, P., Clark, S., & Kalogeras, J. (2002). Voluntary Action and Conscious Awareness. Nature Neuroscience. https://www.nature.com/articles/nn827
- Haggard, P. (2019). The Neurocognitive Bases of Human Volition. Annual Review of Psychology. https://www.annualreviews.org/content/journals/10.1146/annurev-psych-010418-103348
- Kornhuber, H. H., & Deecke, L. (1965). Bereitschaftspotential und reafferente Potentiale. Pflügers Archiv. https://link.springer.com/article/10.1007/BF00412364
- Libet, B., et al. (1983). Time of Conscious Intention to Act in Relation to Onset of Cerebral Activity. Brain. https://academic.oup.com/brain/article-abstract/106/3/623/271932
- Mele, A. R. (2009). Effective Intentions: The Power of Conscious Will. Oxford UP. https://philpapers.org/rec/MELEIT
- Roskies, A. L. (2011). Why Libet's Studies Don't Pose a Threat to Free Will. https://academic.oup.com/book/2344/chapter/142504879
- Schurger, A., Sitt, J. D., & Dehaene, S. (2012). An Accumulator Model for Spontaneous Neural Activity Prior to Self-Initiated Movement. PNAS. https://www.pnas.org/doi/10.1073/pnas.1210467109
- Schurger, A., Hu, P., Pak, J., & Roskies, A. L. (2021). What Is the Readiness Potential? Trends in Cognitive Sciences. https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(21)00093-0
- Soon, C. S., Brass, M., Heinze, H.-J., & Haynes, J.-D. (2008). Unconscious Determinants of Free Decisions in the Human Brain. Nature Neuroscience. https://www.nature.com/articles/nn.2112
Philosophie des Geistes
- Churchland, P. M. (1981). Eliminative Materialism and the Propositional Attitudes. J. Philosophy. https://ruccs.rutgers.edu/images/personal-zenon-pylyshyn/class-info/FP2012_readings/Churchland_EliminativeMaterialsm.pdf
- Frankfurt, H. G. (1969). Alternate Possibilities and Moral Responsibility. J. Philosophy. https://personal.lse.ac.uk/ROBERT49/teaching/ph103/pdf/Frankfurt1969.pdf
- Huxley, T. H. (1874). On the Hypothesis that Animals are Automata, and its History. https://philpapers.org/rec/HUXOTH
- Jackson, F. (1982). Epiphenomenal Qualia. The Philosophical Quarterly. https://academic.oup.com/pq/article-abstract/32/127/127/1612468
- Stanford Encyclopedia of Philosophy: Epiphenomenalism. https://plato.stanford.edu/entries/epiphenomenalism/ · Mental Causation. https://plato.stanford.edu/entries/mental-causation/ · Functionalism. https://plato.stanford.edu/entries/functionalism/ · Emergent Properties. https://plato.stanford.edu/entries/properties-emergent/ · Compatibilism. https://plato.stanford.edu/entries/compatibilism/ · Eliminative Materialism. https://plato.stanford.edu/entries/materialism-eliminative/ · Qualia: The Knowledge Argument. https://plato.stanford.edu/entries/qualia-knowledge/
- Moore, D. (2022). Mind and the Causal Exclusion Problem. IEP. https://iep.utm.edu/mind-and-the-causal-exclusion-problem/
- Yetter-Chappell, H. (2022). Dualism All the Way Down. Synthese. https://philarchive.org/rec/YETDAT
Künstliche Intelligenz
- Bereska, L., & Gavves, E. (2024). Mechanistic Interpretability for AI Safety — A Review. https://arxiv.org/abs/2404.14082
- Chen, Y., Benton, J., et al. (Anthropic). (2025). Reasoning Models Don't Always Say What They Think. https://assets.anthropic.com/m/71876fabef0f0ed4/original/reasoning_models_paper.pdf
- Elhage, N., et al. (Anthropic). (2022). Toy Models of Superposition. https://arxiv.org/abs/2209.10652
- Jacovi, A., & Goldberg, Y. (2020). Towards Faithfully Interpretable NLP Systems. ACL. https://arxiv.org/abs/2004.03685
- Lanham, T., et al. (Anthropic). (2023). Measuring Faithfulness in Chain-of-Thought Reasoning. https://arxiv.org/abs/2307.13702
- Lindsey, J., Gurnee, W., Ameisen, E., et al. (Anthropic). (2025). On the Biology of a Large Language Model. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- Olsson, C., et al. (Anthropic). (2022). In-Context Learning and Induction Heads. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
- Rudin, C. (2019). Stop Explaining Black Box Machine Learning Models for High Stakes Decisions. Nature Machine Intelligence. https://arxiv.org/abs/1811.10154
- Templeton, A., et al. (Anthropic). (2024). Scaling Monosemanticity. https://transformer-circuits.pub/2024/scaling-monosemanticity/
- Turpin, M., Michael, J., Perez, E., & Bowman, S. R. (2023). Language Models Don't Always Say What They Think. https://arxiv.org/abs/2305.04388
Management & Organisationspsychologie
- Clatworthy, M., & Jones, M. J. (2003). Financial Reporting of Good News and Bad News. Accounting and Business Research. https://www.researchgate.net/publication/230844935_Financial_Reporting_of_Good_News_and_Bad_News_Evidence_from_Accounting_Narratives
- Cohen, M. D., March, J. G., & Olsen, J. P. (1972). A Garbage Can Model of Organizational Choice. ASQ. https://www.semanticscholar.org/paper/A-Garbage-Can-Model-of-Organizational-Choice.-Cohen-March/0b9695c173c289d03bf6e78572b00e0d31022756
- Fischhoff, B. (1975). Hindsight ≠ Foresight. JEP: HPP. https://www.researchgate.net/publication/10631443_Hindsight_is_not_equal_to_foresight_The_effect_of_outcome_knowledge_on_judgment_under_uncertainty
- Gioia, D. A., & Chittipeddi, K. (1991). Sensemaking and Sensegiving in Strategic Change Initiation. SMJ. https://sms.onlinelibrary.wiley.com/doi/10.1002/smj.4250120604
- Libby, R., & Rennekamp, K. M. (2012). Self-Serving Attribution Bias, Overconfidence, and Management Forecasts. J. Accounting Research. https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1475-679X.2011.00430.x
- Malmendier, U., & Tate, G. (2008). Who Makes Acquisitions? CEO Overconfidence and the Market's Reaction. JFE. https://ideas.repec.org/a/eee/jfinec/v89y2008i1p20-43.html
- Mintzberg, H., & Waters, J. A. (1985). Of Strategies, Deliberate and Emergent. SMJ. https://ideas.repec.org/a/bla/stratm/v6y1985i3p257-272.html
- Roese, N. J., & Vohs, K. D. (2012). Hindsight Bias. Perspectives on Psychological Science. https://journals.sagepub.com/doi/abs/10.1177/1745691612454303
- Simon, H. A. (1955). A Behavioral Model of Rational Choice. QJE. https://academic.oup.com/qje/article-abstract/69/1/99/1919737
- Weick, K. E. (1995). Sensemaking in Organizations. Sage. https://us.sagepub.com/en-us/nam/sensemaking-in-organizations/book4988
- Unternehmensfälle: AOL–Time Warner (Fortune, 2015); HP–Autonomy (Courthouse News, 2022); Quaker–Snapple (Seattle Times, 1997); Microsoft–Nokia (Bloomberg, 2015).


