
A CEO stands on a stage and explains why the company just spent four billion on a competitor. A language model, asked why it gave the answer it gave, produces three crisp bullet points. You, asked why you ordered coffee instead of tea this morning, answer without hesitating.
Three very different systems. One suspiciously similar move. In each case there is a fluent, confident, well-structured explanation — and in each case it is worth asking whether that explanation is the same thing as the mechanism that actually produced the decision.
This essay is not an argument that your reasons are fake, that you have no free will, or that consciousness is a passenger along for the ride. I'll meet some of those grand claims along the way, and mostly I'll argue they're overstated. The question here is narrower and, I think, more useful:
How reliable are our explanations for our own decisions?
The recurring finding across psychology, neuroscience, AI and management is that complex systems are very good at producing explanations that are coherent, useful, and not a faithful description of how the decision was made. That gap is the whole story. Let's walk through three systems that show it — starting with the one that gets paid the most to sound certain.

1. The CEO
Picture the acquisition announcement. The narrative is clean: "This deal accelerates our platform strategy, unlocks cross-sell synergies, and positions us for the AI era." Every analyst nods. Every slide has an arrow pointing up and to the right.
Now ask the awkward question: is that really why the company bought the other company?
Decades of organizational research suggest the tidy rationale and the real process are often different objects. Start with Herbert Simon's bounded rationality: real decision-makers, facing limited time, attention and information, don't maximize — they satisfice, searching until an option is good enough and then stopping (Simon, 1955). The optimal-choice story told afterward is a reconstruction, not the procedure that was run. This is structural, not an accusation of dishonesty — nobody has time to actually compute the optimum.
It can get messier than that. In Cohen, March and Olsen's garbage can model, organizations under ambiguity make decisions when four largely independent streams — problems, solutions, participants, and choice opportunities — happen to collide (Cohen, March & Olsen, 1972). Solutions often go looking for problems, not the other way around. The model was built for "organized anarchies" like universities and isn't a universal law of the firm — but it names a real possibility the press release will never admit: that the decision found the rationale, not the reverse.
Even the word strategy hides this. Henry Mintzberg's distinction between deliberate and emergent strategy points out that the strategy a company actually realizes is frequently a pattern that formed through action and got named "the plan" only in hindsight (Mintzberg & Waters, 1985). (You'll often see "only 10–30% of intended strategy is realized as intended" attributed to this work; treat that number as a textbook rule of thumb, not a measured statistic.)
Why does the backward-built story feel so true to the person telling it? Two well-documented mechanisms. The first is Karl Weick's sensemaking: organizations make sense of events retrospectively, constructing plausible accounts after acting — captured in his borrowed line, "How can I know what I think until I see what I say?" Sensemaking is an interpretive framework validated mostly through case work, and "plausibility over accuracy" is a descriptive emphasis, not a measured ratio — but as a lens on why executives believe their own reconstructions, it's hard to beat. Layered on top is sensegiving: executives don't just interpret, they actively shape the interpretation others receive (Gioia & Chittipeddi, 1991). That study is a single qualitative case, so don't over-read the magnitude — but the existence of deliberate narrative construction in strategy is not in doubt.
Then there's the data you can count. Self-serving attribution is measurable in corporate disclosure: good outcomes get credited to management skill and strategy, bad outcomes get blamed on markets and macro (Clatworthy & Jones, 2003). The direction of that pattern replicates across countries; the exact percentages vary, so hold the direction firmly and the magnitudes loosely. And there's an experimentally demonstrated chain from self-serving attribution → overconfidence → rosier public forecasts (Libby & Rennekamp, 2012).
Overconfidence in particular shows up with a price tag. In a large panel study, Malmendier & Tate (2008) measured CEO overconfidence two independent ways and found overconfident CEOs were roughly 65% more likely to make acquisitions, and the market greeted their deals far more sourly (announcement returns near −90 basis points versus about −12 for others), especially diversifying deals paid for with internal cash. Overconfidence is inferred rather than directly observed, and announcement returns measure expectation, not realized loss — but the link from a measurable trait to value-destroying deals is the most-cited result of its kind.
You can put faces to it, carefully. AOL–Time Warner was sold on a beautiful "convergence" story in January 2000 (~$165 billion); by 2002 the combined company booked a goodwill write-down of roughly $99 billion (Fortune, 2015). Quaker Oats bought Snapple for ~$1.7 billion in 1994 on a distribution-synergy thesis and sold it for ~$300 million in 1997 (Seattle Times, 1997). Microsoft acquired Nokia's phone business for ~$7.2 billion and wrote off ~$7.6 billion — more than it paid — about 18 months later (Bloomberg, 2015).
A caution that matters for the honesty of this whole essay: those numbers are documented, but the leap from "it failed" to "it was really driven by hubris and narrative" is interpretation, not proof. A goodwill write-down records accounting impairment, not cash set on fire; the dot-com crash was an exogenous shock. The HP–Autonomy case is instructive precisely because it was adjudicated: HP wrote down $8.8 billion and blamed ~$5 billion of it on fraud — and a UK court did find that Autonomy executives committed fraud, while also ruling HP's damages claim "substantially exaggerated" and awarding far less (Courthouse News, 2022). The external story ("we were defrauded") was partly true and partly a comfortable narrative — and that mixture is the realistic case. The lesson isn't that executives lie. It's that the explanation is generated by a different system, under different pressures, than the one that made the call.
2. The AI
Now the same move in a system we can actually open up.
Ask a modern language model why it answered the way it did, and you'll get a fluent rationale. Underneath that rationale are billions of arithmetic operations across a learned network. Here we can ask the question precisely, because the field has a precise vocabulary for it. Jacovi & Goldberg (2020) distinguish a plausible explanation (convincing to a human) from a faithful one (accurately reflecting the model's actual reasoning). The nightmare case is the explanation that is plausible and unfaithful — persuasive precisely where it's wrong.
This is not theoretical. Turpin et al. (2023) planted a bias in prompts — for example, quietly arranging multiple-choice examples so the answer was always "(A)." Models followed the bias and switched answers, while their step-by-step "reasoning" never mentioned it, sometimes constructing arguments for a now-wrong choice (accuracy dropped by as much as 36% on some tasks). The stated reasons and the real cause came apart, cleanly, because the experimenters changed only the hidden cause.
It gets sharper with models built to "think out loud." Anthropic (Chen et al., 2025) gave reasoning models a hint that demonstrably flipped their answer, then checked whether the visible reasoning admitted using it. It did so only a minority of the time — averaging ~25% for one model and ~39% for another across hint types, and lower still for the ethically loaded hints. In a separate setup where a model learned to exploit a planted reward "hack" on essentially 100% of attempts, it mentioned the hack in its reasoning less than 2% of the time. And — this is the part that should unsettle anyone who trusts a confident write-up — the unfaithful chains of reasoning were on average longer and more elaborate than the faithful ones. The more articulate explanation was, if anything, the less trustworthy one. (Faithfulness isn't always this bad — Lanham et al., 2023 found models sometimes genuinely depend on their written reasoning, and that it varies by task and even gets worse as models get bigger.)

So far that's behavior. The deeper evidence comes from prying the model open. Mechanistic interpretability has shown you genuinely cannot read a network's computation off its surface: features are stored in superposition, smeared across neurons that each respond to many unrelated things (Elhage et al., 2022). Tools like sparse autoencoders can pull out cleaner, causally real features — clamp the "Golden Gate Bridge" feature and the model starts steering every conversation toward the bridge (Templeton et al., 2024). And the field has found honest-to-goodness mechanisms, like the induction heads that underpin in-context learning (Olsson et al., 2022). These tools don't just reveal that explanations can drift from mechanism; they let us watch it happen.
The cleanest example: in On the Biology of a Large Language Model (Anthropic, 2025), researchers traced how a model adds two-digit numbers like 36 + 59. It does not use the carry-the-one algorithm. It runs parallel circuits — one estimating the rough magnitude, another handling the last digits via something like a lookup table. But ask the model how it added, and it describes... carrying the one. The textbook method it learned to say, not the method it actually ran. The same work found the model sometimes reasons backward from a conclusion it had already settled on, and sometimes states steps disconnected from the circuit producing the answer.
Two honest caveats keep this from becoming a tidy "AI is lying" story. First, interpretability is young: most fully-understood circuits come from small or toy models, attribution graphs are explicitly approximations whose reliability is itself an open question, and nobody has a complete, validated end-to-end account of a frontier model (Bereska & Gavves, 2024). The evidence that explanation can diverge from mechanism is solid; the dream of fully reading off the mechanism is not yet real. Second — and I'll repeat this in the human section because it's the load-bearing caution of the whole essay — calling the model's output "confabulation" borrows a word from human psychology by analogy. A model has no demonstrated introspective channel it is failing to consult. The resemblance is striking and, I'll argue, instructive. It is not evidence that the machinery is the same.
What survives both caveats is the older, broader point Rudin (2019) made about explainable AI generally: an explanation generated separately from a decision is, by construction, not the decision process. It's a story about the decision. Sometimes a good one. Never guaranteed to be the real one.
3. The Human Mind
Now the uncomfortable turn. Why did you choose coffee this morning?
Notice how fast the answer came. "I needed the caffeine." "I always have coffee." "I just felt like it." Immediate, confident, effortless. Now the harder question: how do you actually know that's why?
This is the exact spot where psychology has spent fifty years, and the founding text is Nisbett & Wilson (1977), bluntly titled Telling More Than We Can Know. In one demonstration, shoppers (about 52 of them) evaluated four pairs of nylon stockings laid out left to right. They preferred the rightmost pair about four to one — a pure position effect, since the stockings were identical. Asked why, they gave roughly 80 reasons: superior knit, texture, sheerness. Essentially none mentioned position. When the experimenter asked directly whether the arrangement could have mattered, all but one denied it — often looking at the questioner as if he were slightly dim.
Read that carefully, because it's easy to overstate. It doesn't show people have no access to their own minds. It shows something more specific and more interesting: people misreport the causes of their judgments, smoothly substituting a plausible reason for the real one. The reasons weren't retrieved. They were generated.
The most vivid demonstration is choice blindness. Johansson, Hall and colleagues (2005) showed people pairs of faces, asked which was more attractive, then — by sleight of hand — handed back the rejected face and asked them to explain "their" choice. Most swaps went unnoticed (concurrent detection around 13%), and people fluently justified a choice they had never made: "I picked her because she's got nice earrings," about the face they'd just turned down. The effect has been extended to taste, smell, consumer choices — and, crucially for anyone who thinks "well, my convictions are solid," to political attitudes. During a Swedish election, Hall et al. (2013) covertly reversed people's own survey answers; only ~22% caught the manipulation, and 92% then defended the flipped position as their own.
The scope limits matter, and the original authors are careful about them: these are often near-threshold choices, and detection rises with stronger preferences. Choice blindness does not prove every conviction is hollow. What it proves is sharper: the machinery that justifies a choice will happily justify a choice you didn't make. The narrator doesn't check with the decider.
That "narrator" has a famous neurological portrait. In split-brain patients — whose hemispheres have been surgically disconnected — Michael Gazzaniga documented what he called the left-brain interpreter. Flash an instruction to the mute right hemisphere ("walk"), and the patient stands and walks; ask the talking left hemisphere why, and it confabulates instantly and confidently — "I'm going to get a Coke" (Volz & Gazzaniga, 2017). The explaining system, cut off from the real cause, manufactures one without hesitation or any sense that it's guessing. (This rests on a handful of unusual patients, and Pinto et al. (2017) have challenged the stronger "two separate minds" reading — but note what they challenge and what they don't: the confabulation itself isn't in dispute, only how divided the underlying consciousness is.)
You don't need a severed corpus callosum for this. A cluster of findings shows the pattern is ordinary:
- Cognitive dissonance: in the classic Festinger & Carlsmith (1959) study, people paid just $1 to call a boring task interesting later genuinely rated it as more enjoyable than people paid $20 — the attitude shifted to fit the behavior, then felt like it had been there all along. (Whether the engine is "felt dissonance" or Daryl Bem's cooler self-perception — we infer our own attitudes by watching our own behavior, the way we'd infer a stranger's — is still debated. Both routes undercut the idea of privileged inner access.)
- The illusion of explanatory depth: people rate their understanding of everyday things — zippers, toilets, locks — as high, until you ask them to actually explain the mechanism step by step, at which point their confidence drops sharply (Rozenblit & Keil, 2002). We mistake recognition for understanding — and we don't notice the gap until we're forced to produce the explanation. Tellingly, this illusion is strongest for mechanisms and weak for facts or stories, which is exactly why it bears on the explanation-vs-mechanism theme.
- The introspection illusion: we judge our own biases by looking inward (and finding no feeling of bias) while judging others by their behavior — so we conclude we're less biased than everyone else (Pronin, 2009). The absence of a felt bias gets taken as evidence of objectivity. It's nothing of the sort.
- Metacognition has limits you can measure: how well your confidence tracks your actual performance is partly separable from the performance itself and depends on specific prefrontal regions — disrupt them with TMS and people get worse at knowing how well they did, while doing the task just as well (Fleming & Dolan, 2012). Knowing-that-you-know is its own fallible faculty.
A necessary detour into honesty, because this literature has been badly oversold. The genre of "your unconscious secretly runs everything" leaned heavily on social priming — most famously Bargh et al. (1996), where exposure to age-related words supposedly made people walk away more slowly. A high-powered replication by Doyen et al. (2012) found no such effect — until experimenters were led to expect it, implicating their own behavior, not unconscious priming. That study became a poster child for psychology's replication crisis: a large coordinated effort reproduced only about 36% of published effects, with social-cognition results faring worst (Open Science Collaboration, 2015). A careful meta-analysis finds priming-by-words is real but small (around d ≈ 0.35) and a far narrower claim than "primes you can't see steer your life" (Weingarten et al., 2016).
So I'm not telling you the unconscious is a puppeteer. The popular dual-process picture — fast intuitive "System 1," slow deliberate "System 2" (Evans & Stanovich, 2013) — is a useful vocabulary, not a proven architecture, and serious researchers argue it doesn't carve anything real (Kruglanski & Gigerenzer, 2011). The defensible claim is the modest one, and it's enough: the system that makes a choice and the system that explains it are dissociable, and the explanation can be confident, fluent, and wrong about the cause.
4. Neuroscience
If the mind narrates after the fact, can we catch the brain in the act? This is where things get sensational — and where I want to slow down, because the popular version ("scientists proved free will is an illusion") is exactly the kind of overstatement this essay is built to resist.
The story starts with the readiness potential — a slow build-up of electrical activity over motor areas that precedes voluntary movement, discovered by Kornhuber & Deecke (1965). Then Benjamin Libet (1983) added a twist that became famous. He had people flex a wrist whenever they felt like it, and report — using a fast-moving clock — the moment they first felt the urge to move. The readiness potential began around 550 ms before the movement. The conscious urge ("W") showed up only around 200 ms before. The brain's preparation appeared to precede the conscious decision by about a third of a second.
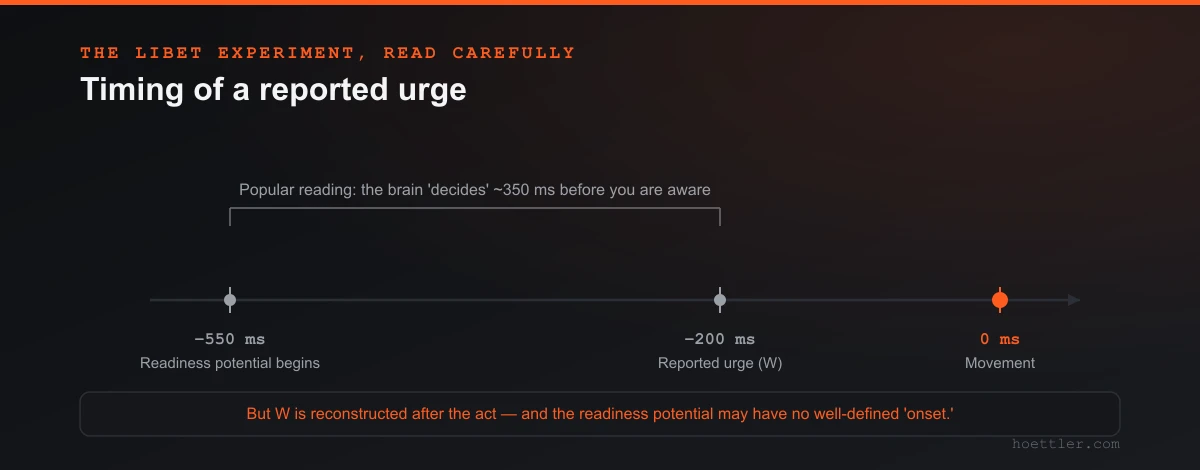
Cue fifty years of headlines. But look at what the experiment actually licenses, and what it doesn't. Three problems, none mystical:
First, the clock you're reading is unreliable. "W" is not a direct readout of an inner event; it's reconstructed partly after the action from sensory cues. Banks & Isham (2009) proved this neatly: play people a deceptive beep a few dozen milliseconds after their keypress, and they report their intention as having occurred later, in lockstep with the fake feedback. The reported moment of "deciding" was being inferred from when they seemed to act — which means it can't be trusted as a timestamp of a prior brain event.
Second, the readiness potential may not be a "decision" at all. Schurger, Sitt & Dehaene (2012) modeled it as a stochastic accumulator: spontaneous neural noise drifting until it crosses a threshold and triggers movement. On this account, the smooth ramp you see is largely an artifact of averaging backward from the movement — line up random fluctuations by their endpoint and they'll look like a rising slope. A follow-up review put the point even more carefully: if the RP is the byproduct of time-locking a noisy process to its threshold crossing, then it has no well-defined "onset" at all, and comparing "RP onset" to "W" is ill-posed (Schurger, Hu, Pak & Roskies, 2021). That's a conditional, not a verdict — defenders of the classical reading dispute it — but it dissolves the clean "the brain decided before you" inference.
Third, the whole edifice is statistically thinner than its fame suggests. The first meta-analysis of Libet-style studies confirmed the basic temporal ordering on average — but found the crucial "RP-precedes-intention" comparison rests on just six studies with high heterogeneity, and that reported timing shifts depending on whether you ask about an "urge" or an "intention" (Braun, Wessler & Friese, 2021). The authors' own word for Libet's foundation: "more fragile than anticipated."
What about the famous fMRI study that decoded choices seconds before awareness? Soon et al. (2008) really did predict which of two buttons people would press up to ~7 seconds ahead — at about 60% accuracy, against a 50% coin flip. Read honestly: predicting a faint bias 10 points above chance is not the decision being made. Most of the choice was unexplained, the choice was arbitrary and stakes-free, and the long lead time partly reflects sluggish blood-flow signals.
Step back. Even taking the data at face value, here's the conflation to avoid: these experiments concern the timing of a reported urge in arbitrary, meaningless movements. They are not about the causal role of consciousness, and they say little about deliberate, reasons-driven choices like whom to hire or whether to take the job. Patrick Haggard, who has spent a career on the neuroscience of volition, stresses exactly this scope limit (Haggard, 2019). Philosophers of action like Alfred Mele (2009) and Adina Roskies argue the results simply don't bear the anti-free-will weight piled on them: an urge is not a decision, and "free will" in the headlines is left undefined.
There's even a framing on which the puzzle dissolves rather than resolves. Under predictive processing / active inference, the brain acts to fulfill its own predictions about what it's about to do, so the neat sequence of intend → then act → then consciousness watches isn't the right picture to begin with (Friston et al., 2013). I flag this as a live theoretical frame, not established fact.
What does survive, and what connects back to our theme, is humbler and sturdier: the brain assembles its sense of "I intended that" and "I did that" partly after the action, from available cues. The feeling of authorship is itself partly a construction — see the robust intentional binding effect, where voluntary actions and their outcomes get pulled together in subjective time (Haggard, Clark & Kalogeras, 2002). Neuroscience hasn't refuted free will. It has shown, again, that the report of a decision and the decision can come apart in time.
5. Philosophy
Only now — after the evidence, not before it — is it fair to introduce the position people reach for first. Epiphenomenalism is the claim that conscious mental states are causally inert by-products of physical processes: T.H. Huxley's image was a steam whistle on a locomotive, riding along, making noise, driving nothing (Huxley, 1874; SEP). On this view your reasons don't merely sometimes misdescribe the cause — they are never the cause; the felt deliberation is the whistle, the neurons are the engine.
It's a tempting place to land after sections 3 and 4. I want to argue you should not land there — not because it's been disproven, but because it is one contested option among several, and the evidence we've seen doesn't single it out.
Here's the standard objection that keeps epiphenomenalism marginal, the paradox of phenomenal judgment (or self-stultification): if your experiences cause nothing physical, then your talking about them — including an epiphenomenalist saying "I have inner experiences" — isn't caused by those experiences either. The view seems to saw off the branch it sits on (SEP). It's telling that the philosopher who gave the position its most famous modern argument, Frank Jackson, later recanted it — reasoning that if qualia were causally idle, we couldn't even know about them (Jackson, 1982; SEP on the Knowledge Argument). (In fairness, it has able defenders still — Yetter-Chappell, 2022 argues the paradox only bites if you're inconsistent about your dualism. The point is that it's live, not that it's true.)
And it's far from the only option. The honest picture is a spread of mutually incompatible, unsettled positions:
- Physicalism says the mental is physical — but faces Jaegwon Kim's causal exclusion worry: if every physical effect already has a sufficient physical cause, the mental property looks redundant, threatening to make your reasons idle by a different route. Exclusion is itself heavily contested (SEP on mental causation) — there are several respectable escape routes — but it's the live problem.
- Functionalism defines mental states by what they do — their causal role — which makes reasons genuine causes almost by definition (SEP). It's arguably the most "your-reasons-are-real" position on the board. Its unfinished business is felt experience: even if the role is causal, the feel riding on it might not be.
- Emergentism asks whether the mental level has genuinely new causal powers (strong emergence) or is just a higher-level description (weak emergence) (SEP). Only the strong version rescues top-down mental causation, and it inherits the same exclusion problem.
- Compatibilism — the dominant view among philosophers — holds free will is compatible with determinism, locating freedom in whether your own reasons, working through normal psychological machinery, drive the act (Frankfurt, 1969; SEP). This is the most direct "yes, reasons cause actions" answer — and it, too, has serious critics.
- Eliminative materialism goes the other way entirely: maybe "beliefs" and "desires" are like "phlogiston," a folk theory destined for replacement, in which case your reasons aren't wrong causes — there are no such things to begin with (Churchland, 1981; SEP). A minority view, with its own self-refutation worry, but unrefuted.

I'm not going to adjudicate this — nobody has, and that's the point. The empirical chapters show, repeatedly, that explanation and mechanism can dissociate. They do not show that consciousness is causally idle, that reasons never cause actions, or which of these six metaphysical pictures is right. Epiphenomenalism is the most dramatic reading available, and drama is precisely why we should be suspicious of how easily we reach for it.
6. What This Means
Strip away the metaphysics and a practical, testable rule remains:
A convincing explanation is not evidence of the mechanism that produced the decision.
That's not nihilism. Explanations are useful — they coordinate teams, transfer knowledge, build trust, and let us argue and improve. The error is confusing the explanation with the mechanism: treating a fluent account of why as a reliable readout of how. Once you hold those apart, a lot of professional life looks different.
Leadership and strategy. Treat the post-hoc rationale as a communication artifact, not a process log. The highest-leverage habit is the cheapest: write the decision down before the outcome — the thesis, the alternatives, the kill-criteria. A dated decision journal is the only real defense against hindsight bias, which silently rewrites your memory of what you expected (Fischhoff, 1975; Roese & Vohs, 2012). Without the written record, every postmortem becomes a story about how you knew all along.
Recruiting. This is where the research bites hardest, because the standard interview is a confabulation-generating machine. "Why did you leave your last role?" "Why do you want this job?" invite exactly the fluent, after-the-fact reasons that Nisbett & Wilson showed are least reliable. The candidate isn't lying; they're narrating. Weight work-sample tests and structured, behavior-anchored questions over introspective self-report — measure the mechanism (can they do the task), not the story about it.
AI safety and product. The faithfulness research is a direct warning: do not treat a model's stated reasoning as a reliable audit of its computation. A model can use a behavior on ~100% of attempts and mention it under 2% of the time (Chen et al., 2025), and its longer, more convincing explanations can be the less faithful ones. Chain-of-thought monitoring can catch frequent, clumsy misbehavior; it cannot certify the absence of the rare or hidden kind. For product, the same caution flips into a UX warning: a confident AI explanation will be persuasive in proportion to its fluency, which is uncorrelated with its truth. Design for verification, not for vibes.
Behavioral economics and design. Choice blindness and the stockings effect mean stated preferences are softer than they feel — defaults and framing move choices people then defend with invented reasons. That's both a tool and a lever for manipulation. Either way: trust revealed behavior over reported preference, and hold your A/B test above your focus group.
Self-understanding. The personal application is the gentlest and maybe the most useful. The feeling of knowing why you did something is produced by a different faculty than the doing — and that faculty, metacognition, is itself fallible and separable from the underlying competence. The move isn't to distrust every reason you have. It's to hold your self-explanations a little more loosely — to notice that "obviously I did it because X" arrives with a confidence that the evidence doesn't earn.
Across all of these, the antidote is the same one this blog keeps circling back to: calibration — holding a belief exactly as strongly as the evidence allows, and not one notch more. (If that idea grabs you, it's the spine of Explaining Is Easy, Predicting Is Hard and Fear Is Not a Probability.)
7. Conclusion
So return to the three figures we started with. The CEO, the language model, and you-with-your-coffee are doing remarkably different things mechanically — a person on a stage, a matrix multiplication, a brain — and yet they share one move: each generates a clean, confident, useful story about a process that was messier, more distributed, and partly inaccessible than the story admits.
Is that resemblance superficial or deep? I've tried to be honest that we don't know. The AI–human comparison is an analogy, and a careful one; the neuroscience is more fragile than its headlines; the philosophy is genuinely unsettled. What recurs across all of them is not a proof about the nature of mind. It's a pattern about the nature of explanation: a sufficiently complex system, asked to account for itself, will produce a narrative optimized for coherence and plausibility — and coherence is not the same as accuracy.
Which leaves the open question this whole essay has been walking toward. Not the loud one — does free will exist? — but the quieter, more answerable one:
Perhaps intelligence is not only the ability to make decisions.
Perhaps it is also the ability to construct explanations that feel convincing — even when they capture only part of what really happened.
If that's right, then the most valuable form of intelligence isn't the fluent explanation at all. It's the humility to ask, of your own most confident account: is this really why? — and to keep the question open a little longer than feels comfortable.
Bibliography
Psychology
- Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity of Social Behavior: Direct Effects of Trait Construct and Stereotype Activation on Action. Journal of Personality and Social Psychology. https://www.semanticscholar.org/paper/Automaticity-of-social-behavior:-direct-effects-of-Bargh-Chen/7244328deba0cd3a4e0096d8fa2dcb5a9285594b
- Bem, D. J. (1972). Self-Perception Theory. Advances in Experimental Social Psychology. https://www.semanticscholar.org/paper/Self-Perception-Theory-Bem/c5f44aa1353a41f7993e4eb383ae45d0b946c17f
- Doyen, S., Klein, O., Pichon, C.-L., & Cleeremans, A. (2012). Behavioral Priming: It's All in the Mind, but Whose Mind? PLOS ONE. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0029081
- Evans, J. St. B. T., & Stanovich, K. E. (2013). Dual-Process Theories of Higher Cognition: Advancing the Debate. Perspectives on Psychological Science. https://journals.sagepub.com/doi/10.1177/1745691612460685
- Festinger, L., & Carlsmith, J. M. (1959). Cognitive Consequences of Forced Compliance. Journal of Abnormal and Social Psychology. https://pubmed.ncbi.nlm.nih.gov/13640824/
- Fleming, S. M., & Dolan, R. J. (2012). The Neural Basis of Metacognitive Ability. Phil. Trans. R. Soc. B. https://pmc.ncbi.nlm.nih.gov/articles/PMC3318765/
- Hall, L., Johansson, P., Tärning, B., Sikström, S., & Strandberg, T. (2013). How the Polls Can Be Both Spot On and Dead Wrong: Using Choice Blindness to Shift Political Attitudes and Voter Intentions. PLOS ONE. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0060554
- Johansson, P., Hall, L., Sikström, S., & Olsson, A. (2005). Failure to Detect Mismatches Between Intention and Outcome in a Simple Decision Task. Science. https://pubmed.ncbi.nlm.nih.gov/16210542/
- Kruglanski, A. W., & Gigerenzer, G. (2011). Intuitive and Deliberate Judgments Are Based on Common Principles. Psychological Review. https://pubmed.ncbi.nlm.nih.gov/21244188/
- Nisbett, R. E., & Wilson, T. D. (1977). Telling More Than We Can Know: Verbal Reports on Mental Processes. Psychological Review. https://home.csulb.edu/~cwallis/382/readings/482/nisbett%20saying%20more.pdf
- Open Science Collaboration (Nosek et al.). (2015). Estimating the Reproducibility of Psychological Science. Science. https://www.science.org/doi/10.1126/science.aac4716
- Pronin, E. (2009). The Introspection Illusion. Advances in Experimental Social Psychology. https://www.sciencedirect.com/science/article/abs/pii/S0022103106000916
- Rozenblit, L., & Keil, F. (2002). The Misunderstood Limits of Folk Science: An Illusion of Explanatory Depth. Cognitive Science. https://pmc.ncbi.nlm.nih.gov/articles/PMC3062901/
- Volz, L. J., & Gazzaniga, M. S. (2017). Interaction in Isolation: 50 Years of Insights from Split-Brain Research. Brain. https://academic.oup.com/brain/article/140/7/2051/3892700
- Pinto, Y., et al. (2017). Split Brain: Divided Perception but Undivided Consciousness. Brain. https://academic.oup.com/brain/article/140/5/1231/2951052
- Weingarten, E., et al. (2016). From Primed Concepts to Action: A Meta-Analysis of the Behavioral Effects of Incidentally-Presented Words. Psychological Bulletin. https://pmc.ncbi.nlm.nih.gov/articles/PMC5783538/
Neuroscience
- Banks, W. P., & Isham, E. A. (2009). We Infer Rather Than Perceive the Moment We Decided to Act. Psychological Science. https://www.antoniocasella.eu/dnlaw/Banks-Isham2009.pdf
- Braun, M. N., Wessler, J., & Friese, M. (2021). A Meta-Analysis of Libet-Style Experiments. Neuroscience & Biobehavioral Reviews. https://pubmed.ncbi.nlm.nih.gov/34119525/
- Friston, K., et al. (2013). The Anatomy of Choice: Active Inference and Agency. Frontiers in Human Neuroscience. https://www.frontiersin.org/journals/human-neuroscience/articles/10.3389/fnhum.2013.00598/full
- Haggard, P., Clark, S., & Kalogeras, J. (2002). Voluntary Action and Conscious Awareness. Nature Neuroscience. https://www.nature.com/articles/nn827
- Haggard, P. (2019). The Neurocognitive Bases of Human Volition. Annual Review of Psychology. https://www.annualreviews.org/content/journals/10.1146/annurev-psych-010418-103348
- Kornhuber, H. H., & Deecke, L. (1965). Hirnpotentialänderungen bei Willkürbewegungen … Bereitschaftspotential. Pflügers Archiv. https://link.springer.com/article/10.1007/BF00412364
- Libet, B., Gleason, C. A., Wright, E. W., & Pearl, D. K. (1983). Time of Conscious Intention to Act in Relation to Onset of Cerebral Activity (Readiness-Potential). Brain. https://academic.oup.com/brain/article-abstract/106/3/623/271932
- Mele, A. R. (2009). Effective Intentions: The Power of Conscious Will. Oxford University Press. https://philpapers.org/rec/MELEIT
- Roskies, A. L. (2011). Why Libet's Studies Don't Pose a Threat to Free Will. In Conscious Will and Responsibility. https://academic.oup.com/book/2344/chapter/142504879
- Schurger, A., Sitt, J. D., & Dehaene, S. (2012). An Accumulator Model for Spontaneous Neural Activity Prior to Self-Initiated Movement. PNAS. https://www.pnas.org/doi/10.1073/pnas.1210467109
- Schurger, A., Hu, P., Pak, J., & Roskies, A. L. (2021). What Is the Readiness Potential? Trends in Cognitive Sciences. https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(21)00093-0
- Soon, C. S., Brass, M., Heinze, H.-J., & Haynes, J.-D. (2008). Unconscious Determinants of Free Decisions in the Human Brain. Nature Neuroscience. https://www.nature.com/articles/nn.2112
Philosophy of mind
- Churchland, P. M. (1981). Eliminative Materialism and the Propositional Attitudes. Journal of Philosophy. https://ruccs.rutgers.edu/images/personal-zenon-pylyshyn/class-info/FP2012_readings/Churchland_EliminativeMaterialsm.pdf
- Frankfurt, H. G. (1969). Alternate Possibilities and Moral Responsibility. Journal of Philosophy. https://personal.lse.ac.uk/ROBERT49/teaching/ph103/pdf/Frankfurt1969.pdf
- Huxley, T. H. (1874). On the Hypothesis that Animals are Automata, and its History. https://philpapers.org/rec/HUXOTH
- Jackson, F. (1982). Epiphenomenal Qualia. The Philosophical Quarterly. https://academic.oup.com/pq/article-abstract/32/127/127/1612468
- Stanford Encyclopedia of Philosophy: Epiphenomenalism (Robinson, 2023). https://plato.stanford.edu/entries/epiphenomenalism/ · Mental Causation (Robb & Heil, 2023). https://plato.stanford.edu/entries/mental-causation/ · Functionalism (Levin, 2023). https://plato.stanford.edu/entries/functionalism/ · Emergent Properties (O'Connor & Wong, 2024). https://plato.stanford.edu/entries/properties-emergent/ · Compatibilism (McKenna & Coates, 2024). https://plato.stanford.edu/entries/compatibilism/ · Eliminative Materialism (Ramsey, 2024). https://plato.stanford.edu/entries/materialism-eliminative/ · Qualia: The Knowledge Argument (Nida-Rümelin & O'Conaill, 2024). https://plato.stanford.edu/entries/qualia-knowledge/
- Moore, D. (2022). Mind and the Causal Exclusion Problem. Internet Encyclopedia of Philosophy. https://iep.utm.edu/mind-and-the-causal-exclusion-problem/
- Yetter-Chappell, H. (2022). Dualism All the Way Down: Why There Is No Paradox of Phenomenal Judgment. Synthese. https://philarchive.org/rec/YETDAT
Artificial intelligence
- Bereska, L., & Gavves, E. (2024). Mechanistic Interpretability for AI Safety — A Review. https://arxiv.org/abs/2404.14082
- Chen, Y., Benton, J., et al. (Anthropic). (2025). Reasoning Models Don't Always Say What They Think. https://assets.anthropic.com/m/71876fabef0f0ed4/original/reasoning_models_paper.pdf
- Elhage, N., et al. (Anthropic). (2022). Toy Models of Superposition. https://arxiv.org/abs/2209.10652
- Jacovi, A., & Goldberg, Y. (2020). Towards Faithfully Interpretable NLP Systems. ACL. https://arxiv.org/abs/2004.03685
- Lanham, T., et al. (Anthropic). (2023). Measuring Faithfulness in Chain-of-Thought Reasoning. https://arxiv.org/abs/2307.13702
- Lindsey, J., Gurnee, W., Ameisen, E., et al. (Anthropic). (2025). On the Biology of a Large Language Model. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- Olsson, C., et al. (Anthropic). (2022). In-Context Learning and Induction Heads. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
- Rudin, C. (2019). Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nature Machine Intelligence. https://arxiv.org/abs/1811.10154
- Templeton, A., et al. (Anthropic). (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. https://transformer-circuits.pub/2024/scaling-monosemanticity/
- Turpin, M., Michael, J., Perez, E., & Bowman, S. R. (2023). Language Models Don't Always Say What They Think. https://arxiv.org/abs/2305.04388
Management & organizational psychology
- Clatworthy, M., & Jones, M. J. (2003). Financial Reporting of Good News and Bad News: Evidence from Accounting Narratives. Accounting and Business Research. https://www.researchgate.net/publication/230844935_Financial_Reporting_of_Good_News_and_Bad_News_Evidence_from_Accounting_Narratives
- Cohen, M. D., March, J. G., & Olsen, J. P. (1972). A Garbage Can Model of Organizational Choice. Administrative Science Quarterly. https://www.semanticscholar.org/paper/A-Garbage-Can-Model-of-Organizational-Choice.-Cohen-March/0b9695c173c289d03bf6e78572b00e0d31022756
- Fischhoff, B. (1975). Hindsight ≠ Foresight: The Effect of Outcome Knowledge on Judgment Under Uncertainty. JEP: HPP. https://www.researchgate.net/publication/10631443_Hindsight_is_not_equal_to_foresight_The_effect_of_outcome_knowledge_on_judgment_under_uncertainty
- Gioia, D. A., & Chittipeddi, K. (1991). Sensemaking and Sensegiving in Strategic Change Initiation. Strategic Management Journal. https://sms.onlinelibrary.wiley.com/doi/10.1002/smj.4250120604
- Libby, R., & Rennekamp, K. M. (2012). Self-Serving Attribution Bias, Overconfidence, and the Issuance of Management Forecasts. Journal of Accounting Research. https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1475-679X.2011.00430.x
- Malmendier, U., & Tate, G. (2008). Who Makes Acquisitions? CEO Overconfidence and the Market's Reaction. Journal of Financial Economics. https://ideas.repec.org/a/eee/jfinec/v89y2008i1p20-43.html
- Mintzberg, H., & Waters, J. A. (1985). Of Strategies, Deliberate and Emergent. Strategic Management Journal. https://ideas.repec.org/a/bla/stratm/v6y1985i3p257-272.html
- Roese, N. J., & Vohs, K. D. (2012). Hindsight Bias. Perspectives on Psychological Science. https://journals.sagepub.com/doi/abs/10.1177/1745691612454303
- Simon, H. A. (1955). A Behavioral Model of Rational Choice. Quarterly Journal of Economics. https://academic.oup.com/qje/article-abstract/69/1/99/1919737
- Weick, K. E. (1995). Sensemaking in Organizations. Sage. https://us.sagepub.com/en-us/nam/sensemaking-in-organizations/book4988
- Company cases: AOL–Time Warner (Fortune, 2015); HP–Autonomy (Courthouse News, 2022); Quaker–Snapple (Seattle Times, 1997); Microsoft–Nokia (Bloomberg, 2015).


